

摘要
在 ROS 2 多机联调里,一个常见现象是:两台机器网络互通,ros2 topic list 能看到对端 Topic,但执行 ros2 topic echo 时没有任何输出。
这类问题的根因通常不在业务逻辑本身,而在通信链路没有真正打通。最常见的方向有两类:发现层通了但数据层没通,以及发布端和订阅端 QoS 不兼容。也就是说,看到 Topic 不等于已经收到数据。
下文按工程排障顺序展开:先看环境是否一致,再验证发现层,再检查 Topic 与 QoS,再用最小闭环隔离业务干扰,最后处理多网卡、Docker 和大消息等高频场景。
补一个适用前提:下文大多数排障步骤都基于 DDS 系 RMW,例如 Fast DDS、Cyclone DDS。若当前使用的是 rmw_zenoh,发现机制与配置入口不同,应按 rmw_zenoh 文档单独排查。
一、问题现象
典型表现如下:
- 两台机器可以互相
ping ros2 topic list能看到对端发布的 Topicros2 node list、rqt_graph看起来也像是“通了”- 但执行
ros2 topic echo /xxx时,没有任何数据输出
ros2 topic list 反映的是图信息和发现结果,ros2 topic echo 验证的则是订阅端是否真正收到业务数据。两者对应的不是同一个判断层次,所以“能看到 Topic”并不能直接说明数据链路已经打通。
排障时,真正决定 echo 能不能收到数据的,通常是下面几个条件是否同时成立:
- 发布端和订阅端是否真的完成匹配
- Topic 类型是否一致
- QoS 是否兼容
- 数据通路是否真实可达
- RMW / DDS 配置是否一致
二、通信原理
(一)发现层与数据层
ROS 2 / DDS 的通信过程可以粗略拆成两层:
- 发现层:先发现远端 participant,再发现对端的 writer 和 reader
- 数据层:在端点满足匹配条件之后,真正传输业务数据
这两层虽然相关,但不是一回事。很多“图里看得见”的现象仍然停留在发现层;真正的故障,往往出在数据层。
(二)QoS 对通信的影响
QoS 是这类问题里最容易被忽略、也最容易直接影响结论的因素。很多时候,Topic 名字对了、类型也对,但 echo 仍然没有数据,根因其实是 QoS 不兼容。
这里先记一个排障顺序:先看 reliability 和 durability,再看 history / depth 等缓存行为。 具体检查方法放到后面的“Topic 与 QoS 检查”一节展开。
三、排障思路
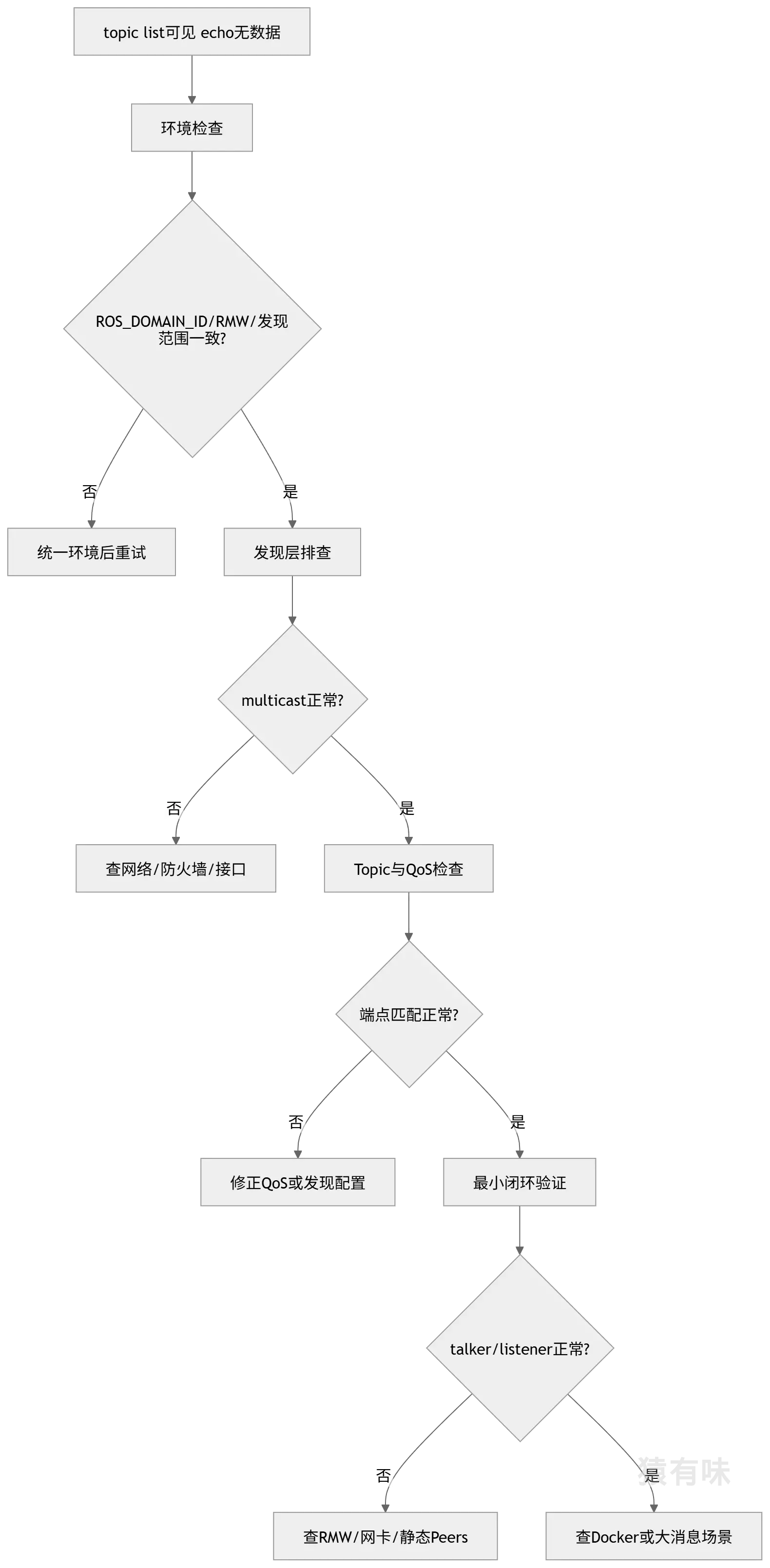
(一)总体策略
这类问题不建议一开始就改配置,也不建议优先怀疑业务代码。更有效的做法通常是按层排查:
- 先确认两台机器的运行环境是不是一致
- 再确认发现层是不是正常
- 再看 Topic、类型和 QoS 能不能匹配上
- 再用最小 demo 验证是不是基础通信问题
- 最后再查多网卡、Docker、共享内存、大消息这些特殊场景
这样可以减少在业务代码和网络层之间反复切换带来的误判。
(二)建议排查顺序
四、环境检查
(一)先看 ROS_DOMAIN_ID
第一步,先在两台机器都执行:
echo $ROS_DOMAIN_ID
如果两边不一致,就不用继续往下猜了。 因为节点根本不在同一个 DDS Domain 里,后面无论看到什么现象,都没有太大参考意义。
为了更完整一点,建议把关键环境变量一次性看全:
env | grep -E 'ROS_DOMAIN_ID|ROS_LOCALHOST_ONLY|ROS_AUTOMATIC_DISCOVERY_RANGE|ROS_STATIC_PEERS|RMW_IMPLEMENTATION|CYCLONEDDS_URI|FASTDDS_DEFAULT_PROFILES_FILE|FASTRTPS_DEFAULT_PROFILES_FILE'
很多时候,问题不是出在某一个变量上,而是几项配置叠加后的结果。
(二)单独检查 ROS_LOCALHOST_ONLY
排多机通信问题时,单独确认ROS_LOCALHOST_ONLY:
echo $ROS_LOCALHOST_ONLY
如果这里是:
1
那就意味着 ROS 2 通信会被限制在本机,多机通信会直接失效,其他机器看不到这些 topics、services 和 actions。
这类问题在旧开发机、复制来的 .bashrc / .zshrc、或者历史调试环境里很常见。排多机问题时,建议优先确认它未被设置,或者明确设为:
export ROS_LOCALHOST_ONLY=0
(三)再看 RMW_IMPLEMENTATION
查看当前使用的 RMW:
echo $RMW_IMPLEMENTATION
如果这里什么都没输出,不表示“当前没有使用 RMW”,而是表示当前 shell 没有显式设置 RMW_IMPLEMENTATION 这个环境变量。按照 ROS 2 官方文档的口径,这时通常可以先按当前发行版默认 RMW来理解;但如果你的环境是源码构建、定制安装,默认实现也可能在构建阶段被改掉,现场排障建议显式确认。
这也是现场里容易误判的地方:两台机器上这个命令都“空着”,并不等于它们实际跑的是同一个 RMW。下面这些情况都可能导致默认实现不同:
- 两台机器安装的 ROS 2 发行版、补丁版本或依赖包不完全一致
- 一台机器在某个终端里手动
export过,另一台没有 - 节点是从 Docker、systemd、SSH 非登录 shell、IDE 启动的,继承到的环境和你当前手工排查的终端并不一致
所以当 echo $RMW_IMPLEMENTATION 没有输出时,排障不要停在“看起来没问题”,而是建议直接做两件事:
- 在两台机器上、用于实际启动节点的同一个终端里,显式设置成同一个 RMW
- 重新加载环境并重启节点后再测,不要拿旧进程或旧终端里的状态做判断
如果一台机器跑的是:
rmw_fastrtps_cpp
另一台跑的是:
rmw_cyclonedds_cpp
建议先统一,再往下排。
理论上不同实现并不等于一定不能通信,但实际联调中,只要两边中间件、配置文件、网络接口策略不一致,现场现象就会明显变复杂。排障阶段更稳妥的做法是先把变量收敛。
临时统一为 Cyclone DDS:
export RMW_IMPLEMENTATION=rmw_cyclonedds_cpp
临时统一为 Fast DDS:
export RMW_IMPLEMENTATION=rmw_fastrtps_cpp
如果你之前执行 echo $RMW_IMPLEMENTATION 没有任何输出,排障阶段应该显式 export,把“默认值到底是什么”这个不确定因素先消掉。
(四)检查发现范围
如果环境里设置了下面这些变量,重点看:
echo $ROS_AUTOMATIC_DISCOVERY_RANGE
echo $ROS_STATIC_PEERS
先补一个边界条件:ROS 2 官方的 Improved Dynamic Discovery 文档明确说明,ROS_AUTOMATIC_DISCOVERY_RANGE 和 ROS_STATIC_PEERS 不适用于 rmw_zenoh。如果你当前使用的是 rmw_zenoh,就不要再按这一节的 DDS 发现逻辑继续排,而应该改看 rmw_zenoh 自己的配置文档。
尤其是下面几种情况最容易出问题:
LOCALHOST:只在本机发现OFF:直接关闭自动发现SYSTEM_DEFAULT:不主动修改发现配置,交给底层中间件默认行为- 配了
ROS_STATIC_PEERS,但地址写错、写漏,或者两边策略不一致
另外再注意一个细节:官方文档里 ROS_STATIC_PEERS 的格式是分号分隔的地址列表,而不是空格分隔。地址本身写对了但分隔方式不对,也会让排查结果非常迷惑。
这类配置适合做受控环境下的通信收敛;但在多机联调阶段,如果忘了改过它,就很容易把问题带偏。
(五)检查 DDS 配置文件
如果你使用的是 Cyclone DDS,就看:
echo $CYCLONEDDS_URI
如果你使用的是 Fast DDS,就看:
echo $FASTDDS_DEFAULT_PROFILES_FILE
echo $FASTRTPS_DEFAULT_PROFILES_FILE
这一步非常关键。因为很多现场看起来像“网络偶发异常”,其实本质上是:
- 一台机器加载了自定义 XML
- 另一台没加载
- 或者两边都加载了,但不是同一份配置
这种情况下,现场现象往往很混乱:有时能发现,有时不能发现;有时能看到 Topic,但始终收不到数据。建议先把配置来源统一,再继续排。
(六)修改配置后,先刷新 CLI 状态再重测
无论你改的是:
RMW_IMPLEMENTATIONROS_AUTOMATIC_DISCOVERY_RANGEROS_STATIC_PEERSCYCLONEDDS_URI- Fast DDS / Cyclone DDS 的 XML 配置
都不要改完马上盯着旧现象下结论。DDS 相关配置通常只在进程启动时读取一次,而 ros2 CLI 自己还有后台 daemon 缓存图信息。不刷新这些状态,就很容易出现“明明改了配置,但 topic list / node list 看起来还是老样子”的假象。
更稳妥的做法是:
- 在当前终端重新
sourceROS 环境和工作区 overlay - 执行
ros2 daemon stop,清掉旧的图缓存 - 重启相关节点或重新启动容器 / 服务
- 再重新执行
ros2 topic list、ros2 topic info --verbose和ros2 topic echo
常用操如下:
source /opt/ros/<你的发行版>/setup.bash
source <你的工作区>/install/setup.bash
ros2 daemon stop
补充两点:
ros2 daemon stop主要是为了避免 CLI 继续读到旧图信息;下一次执行 ROS 2 CLI 命令时,它会按需重新拉起- 如果节点跑在 Docker、systemd 或其他守护进程里,仅修改你当前 shell 的环境变量并不会自动影响已经在运行的进程,必须重启对应容器或服务
五、发现层排查
(一)先测 multicast
如果你怀疑发现层有问题,最直接的做法就是先测 multicast。
机器 A 执行:
ros2 multicast receive
机器 B 执行:
ros2 multicast send
如果这一步不通,就先别急着去看业务节点。因为这说明最基础的发现链路本身就可能有问题。
(二)检查防火墙和网络设备
如果 A 没有收到类似 Hello World! 的内容,优先检查:
- 主机防火墙
- 路由器 / 交换机是否限制组播
- 公司网络、校园网、VPN 是否对 multicast 做了限制
Linux 上如果启用了 ufw,可以先做一轮最基本的放行测试:
sudo ufw allow in proto udp to 224.0.0.0/4
sudo ufw allow in proto udp from 224.0.0.0/4
先验证问题是不是因为组播被挡住,再决定后续要不要做更细的网络策略收敛。
(三)检查网卡是否支持 multicast
有时问题不在 ROS 2,也不在 DDS,而是在网卡层面就不具备预期能力,或者系统选错了接口。
先看网卡:
ifconfig
或者:
ip addr
如果使用 ifconfig,要留意接口 flags 里有没有 MULTICAST。 如果连发现层都不正常,就没必要优先怀疑业务 Topic 本身。
六、Topic 与 QoS 检查
(一)查看 Topic 详情
先执行:
ros2 topic info /你的topic --verbose
这条命令可以直接输出下面几类信息:
- Topic 类型
- Publisher / Subscriber 数量
- 节点名与命名空间
- QoS profiles
很多时候,只要把这条命令的输出看清楚,问题范围就能明显缩小。
(二)判断订阅是否真的建立
重点先看:
Topic typePublisher countSubscription count
然后另开一个终端执行:
ros2 topic echo /你的topic
再回来看 Subscription count 是否增加。
这里有两种常见判断:
- Subscription count 增加了,但依然没数据 更像是数据路径问题,或者数据本身没真正送达
- Subscription count 根本没形成有效变化或匹配异常 更应该优先怀疑 QoS、类型,或者发现配置本身有问题
(三)先盯兼容性,再看缓存行为
QoS 不需要一开始全看。排查“端点能不能先匹配上”时,优先看:
ReliabilityDurability
尤其是 best_effort / reliable 不一致、volatile / transient_local 不一致时,表面现象非常像“消息没有发出来”,但本质上是端点根本没按预期匹配成功。
History / Depth 也值得看,但它更多影响的是缓存与行为表现,例如你能看到多少历史样本、晚加入订阅者看起来会不会“像没收到”。它通常不是判断端点能否匹配成功的主轴,所以排障顺序上应当放在 reliability 和 durability 后面。
七、最小闭环验证
(一)先跑 talker 和 listener
当你已经怀疑问题不在业务逻辑时,更有效的做法通常是先跑一个最小闭环。
机器 A:
ros2 run demo_nodes_cpp talker
机器 B:
ros2 run demo_nodes_cpp listener
如果这一步都不通,基本就可以判断:问题在基础通信层,而不是你的业务节点。
(二)怎么判断是基础层问题还是业务层问题
经验上可以直接这样分:
- 最小 demo 不通 优先查网络、RMW、DDS 配置、发现范围、网卡选择
- 最小 demo 正常,业务 Topic 不通 优先查业务 Topic 的 QoS、消息类型、命名空间、特殊 DDS 配置
如果你希望显式指定 RMW 再验证,也可以这么做:
export RMW_IMPLEMENTATION=rmw_cyclonedds_cpp
ros2 run demo_nodes_cpp talker
另一台:
export RMW_IMPLEMENTATION=rmw_cyclonedds_cpp
ros2 run demo_nodes_cpp listener
这样做的目的是先把变量压缩掉,让现场更可读。
八、特殊 Topic 排查
(一)传感器 Topic
传感器类 Topic 经常不是默认 QoS。 很多视觉、雷达、点云、IMU 相关数据更偏向低延迟,而不是强可靠。所以这类 Topic 最容易出现一种错觉:
- Topic 名字没问题
- 发布端也在发
- 但你默认
echo就是收不到
这个时候不要只盯着 Topic 名字看,一定先看它实际提供的 QoS:
ros2 topic info /你的topic --verbose
先把发布端 QoS 看清楚,再决定是否手动指定 echo 参数。
(二)/tf_static
/tf_static 是一个非常容易误判的 Topic。 它不是普通的 volatile 实时流,而是带有明显 QoS 特征的静态数据分发场景。
这里需要明确一点:ROS 2 最新官方 tf2 教程里,已经直接使用了:
ros2 topic echo /tf_static
这意味着在较新的发行版或 CLI 行为下,默认命令有可能直接看到数据。
但从 QoS 原理上看,transient_local 发布端配 volatile 订阅端,虽然是兼容的,却只能拿到新消息,拿不到订阅建立之前已经发过的历史样本。/tf_static 恰恰又常常是在节点启动时就发一次,所以你如果是“晚启动的 echo”,默认命令仍然非常容易表现成“没有数据”。
排查时建议直接用下面这种方式看:
ros2 topic echo --qos-reliability reliable --qos-durability transient_local /tf_static
如果你直接执行默认的:
ros2 topic echo /tf_static
在一些现场里也许能看到数据,但如果看不到,很多时候并不代表发布端没发,而只是你的订阅方式没有拿到历史样本。排障时不建议依赖默认 ros2 topic echo /tf_static 的行为去判断是否发布成功;为了先排除 QoS 影响,优先显式指定 reliable + transient_local 更稳。
九、多网卡与静态 Peers
(一)多网卡为什么经常坑 DDS
如果一台机器上同时存在下面这些接口:
- 有线网卡
- Wi-Fi
- Docker 虚拟网卡
- VPN
- WSL2 / Hyper-V 虚拟网卡
DDS 很可能自动选错接口。
一旦选错,问题就会变得特别隐蔽: 你能看到 Topic,说明某些发现信息可能已经绕过去了;但真正的数据地址通告出去以后,对端根本到不了,于是 echo 就一直没数据。
所以多网卡场景下,一个非常核心的思路就是:不要完全相信自动选路,必要时手动指定接口。
(二)显式指定 Cyclone DDS 网卡
先设置环境变量:
export RMW_IMPLEMENTATION=rmw_cyclonedds_cpp
export CYCLONEDDS_URI=file://$HOME/.ros/cyclonedds.xml
创建配置文件:
mkdir -p ~/.ros
vim ~/.ros/cyclonedds.xml
写入最小配置:
<?xml version="1.0" encoding="UTF-8"?>
<CycloneDDS xmlns="https://cdds.io/config">
<Domain>
<General>
<Interfaces>
<NetworkInterface name="eth0"/>
</Interfaces>
</General>
</Domain>
</CycloneDDS>
如果真实网卡不是 eth0,先查:
ip addr
然后替换成实际接口名。
这个办法在多网卡、WSL2、Docker、VPN 混杂环境里尤其有效,因为它直接去掉了“接口自动选择错误”这个不确定因素。
(三)配置静态 Peers
如果组播发现不稳定,或者网络环境本身不适合依赖自动发现,也可以直接指定 peers。
例如:
<?xml version="1.0" encoding="UTF-8"?>
<CycloneDDS xmlns="https://cdds.io/config">
<Domain>
<General>
<Interfaces>
<NetworkInterface name="eth0"/>
</Interfaces>
</General>
<Discovery>
<Peers>
<Peer Address="192.168.10.10"/>
<Peer Address="192.168.10.11"/>
</Peers>
</Discovery>
</Domain>
</CycloneDDS>
这样做可以减少对自动 multicast 发现的依赖。在跨网段、受限网络、公司内网或者虚拟化环境里,这往往比单纯依赖默认发现更稳。
(四)WSL2 场景更容易“能 list,不能 echo”
如果其中一端跑在 WSL2 里,这类问题通常更隐蔽。WSL2 对 ROS 2 / DDS 来说并不是“普通 Linux 物理机直连网卡”,而是带有虚拟化网络层的环境。现场里经常会同时出现:
- WSL2 虚拟网卡
- Windows 宿主机相关接口
- 物理网卡映射出来的地址
- Docker / VPN / Hyper-V 附加接口
这类环境最典型的问题,是接口和地址自动选择不稳定。结果往往不是“完全不通”,而是:
ros2 topic list看起来正常- 但真正收数时地址选错,
ros2 topic echo没反应
这类场景里,Cyclone DDS 之所以能恢复,关键通常不是“单纯换了中间件”,而是:
- 用
NetworkInterface显式固定了真实要走的接口,比如eth3 - 用
Peers把远端地址显式写死,减少了对自动发现和自动选路的依赖
真正起作用的是把接口选择和发现路径都收敛了。因此在 WSL2、Hyper-V、VPN、多虚拟网卡混杂的环境里,排查上最有价值的经验通常有:
topic list能看到,不代表 WSL2 里的业务数据回程地址就一定正确- 如果默认 Fast DDS 或默认 Cyclone DDS 表现不稳定,先不要急着怀疑业务节点,优先显式指定接口和 peers
十、Fast DDS 排查
(一)先确认当前是不是 Fast DDS
echo $RMW_IMPLEMENTATION
如果输出是:
rmw_fastrtps_cpp
说明当前走的是 Fast DDS 这条链路。
(二)检查 XML 配置是否一致
接着看:
echo $FASTDDS_DEFAULT_PROFILES_FILE
echo $FASTRTPS_DEFAULT_PROFILES_FILE
如果两边配置文件不一致,或者一边加载了配置、一边没加载,建议先统一。
这一点很重要,因为很多 Fast DDS 场景下的问题,并不是中间件本身异常,而是两边运行参数根本不是同一套。
(三)“能发现”不等于“能传数据”
Fast DDS 下如果出现“topic list 能看到,但 echo 没数据”,更常见的情况是接口选择、locator 通告、QoS 或 XML 配置没有真正对齐。
在 WSL2、多网卡、虚拟网卡混杂环境里,这类问题尤其常见,因此 Fast DDS 排查的重点通常是尽快把接口、locator 和 peers 收敛下来。
(四)Fast DDS 参考 XML
如果你已经确认:
- 一端运行在 WSL2
- 默认
rmw_fastrtps_cpp下可以list,但echo收不到 - 改成 Cyclone DDS,并显式指定接口和 peers 后恢复
那 Fast DDS 也不要继续完全依赖默认自动选路。更稳妥的做法是显式提供 XML,把接口白名单、发现流量 locator、业务数据 locator 和 静态 peers 一次性固定下来。
先设置环境变量:
export RMW_IMPLEMENTATION=rmw_fastrtps_cpp
export FASTDDS_DEFAULT_PROFILES_FILE=$HOME/.ros/fastdds.xml
export FASTRTPS_DEFAULT_PROFILES_FILE=$HOME/.ros/fastdds.xml
unset CYCLONEDDS_URI
然后创建配置文件:
mkdir -p ~/.ros
vim ~/.ros/fastdds.xml
参考配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<dds xmlns="http://www.eprosima.com/XMLSchemas/fastRTPS_Profiles">
<profiles>
<transport_descriptors>
<transport_descriptor>
<transport_id>udp_transport_eth3</transport_id>
<type>UDPv4</type>
<interfaceWhiteList>
<address>192.168.10.54</address>
</interfaceWhiteList>
</transport_descriptor>
</transport_descriptors>
<participant profile_name="ros2_wsl2_fastdds_profile" is_default_profile="true">
<rtps>
<useBuiltinTransports>false</useBuiltinTransports>
<userTransports>
<transport_id>udp_transport_eth3</transport_id>
</userTransports>
<builtin>
<metatrafficUnicastLocatorList>
<locator>
<udpv4>
<address>192.168.10.54</address>
</udpv4>
</locator>
</metatrafficUnicastLocatorList>
<initialPeersList>
<locator>
<udpv4>
<address>192.168.10.54</address>
</udpv4>
</locator>
<locator>
<udpv4>
<address>192.168.10.22</address>
</udpv4>
</locator>
<locator>
<udpv4>
<address>192.168.10.11</address>
</udpv4>
</locator>
</initialPeersList>
</builtin>
<defaultUnicastLocatorList>
<locator>
<udpv4>
<address>192.168.10.54</address>
</udpv4>
</locator>
</defaultUnicastLocatorList>
</rtps>
</participant>
</profiles>
</dds>
这个参考配置和上面的 Cyclone DDS 配置思路一致:
interfaceWhiteList:只允许 Fast DDS 使用你指定接口上的地址。为了兼容不同版本的 XML 解析器,更建议直接写 IP 地址,而不是接口名metatrafficUnicastLocatorList:显式指定本机用于接收发现流量的单播地址,避免继续依赖默认接口选择initialPeersList:把已知对端地址写进去,减少对自动 multicast 发现的依赖;如果你采用静态 peers 思路,建议把本机实际 IP也一起写进去defaultUnicastLocatorList:显式指定本机用于接收业务数据流量的单播地址;如果这一项没固定,现场就很容易出现“能list,但echo没数据”
使用时注意几个细节:
192.168.10.54要替换成当前这台机器实际局域网 IP192.168.10.22、192.168.10.11要替换成实际对端地址- 如果
ros2一启动就出现Invalid element found into 'interfaceWhiteList',优先把<interface>网卡名</interface>改成<address>本机IP</address>;有些现场版本的 Fast DDS XML 解析器对接口名写法支持并不一致 - 如果使用
initialPeersList后连同机talker/listener都互相看不到,优先检查是不是漏写了本机自己的 IP;实测在 WSL2 + Fast DDS 下,这一项缺失会直接导致list/echo异常 - 如果你已经能
list但仍然不能echo,优先检查是不是漏配了defaultUnicastLocatorList - 为了兼容不同版本的 Fast DDS / rmw_fastrtps 习惯,
FASTDDS_DEFAULT_PROFILES_FILE和FASTRTPS_DEFAULT_PROFILES_FILE可以同时指向同一份 XML - 如果你在 Cyclone DDS 和 Fast DDS 之间来回切换,建议同时清理无关环境变量,例如切到 Fast DDS 时执行
unset CYCLONEDDS_URI - 改完 XML 后,记得重新
source环境、执行ros2 daemon stop,并重启相关节点再测
如果你不希望进一步收敛发现流量,至少也建议保留接口白名单,先排除“选错虚拟网卡”这一类高频问题。
十一、Docker 场景排查
(一)宿主机和容器之间最容易出现假象
Docker 场景里经常出现一种错觉:看起来像多机通信问题,实际上是宿主机和容器之间的本地通信问题。
表面现象也很像:
topic list能看到echo却一直没数据
(二)--network=host 还不够,很多时候还要 --ipc=host
如果你在 Docker 里用了 --network=host,不要自动认为这就万事大吉了。
在某些 DDS 实现里,宿主机和容器会因为网络命名空间的表现被当作“同一主机”来处理;但如果共享内存空间没有打通,SHM 路径依然可能失效,最终就会出现一种很别扭的现象:发现能看到,数据却过不来。
错误示例:
docker run -it --rm --network=host your_image
更稳妥的方式通常是:
docker run -it --rm --network=host --ipc=host your_image
(三)怎么判断是不是 SHM / IPC 问题
如果同时满足下面几个条件,就要优先往 SHM / IPC 方向怀疑:
- 问题发生在宿主机和容器之间
- 或同一宿主机上的多个容器之间
- 并且使用了
--network=host topic list可见,但echo无数据
这种场景下,不要只盯着 QoS 和防火墙,--ipc=host 往往才是关键点。
十二、大消息排查
(一)图像、点云、大数组最容易出现“似通非通”
如果问题不是“完全没数据”,而是:
- 很久才来一条
- 一会儿正常,一会儿卡住
- 图像、点云、大数组 Topic 明显异常
那就不能只从发现和 QoS 去看了。 这类问题很多时候已经下沉到网络层、UDP 分片、内核缓冲区,甚至 DDS 大包传输策略。
(二)先看 ipfrag_time
先查看当前值:
sysctl net.ipv4.ipfrag_time
临时修改为 3 秒:
sudo sysctl net.ipv4.ipfrag_time=3
这一步不是“万能修复”,但在大消息、Wi-Fi、有丢包或抖动的链路里值得检查。
官方 DDS tuning 文档还给了另一个常见方向:如果问题本质上是 IP 分片重组缓存太小,也可以继续检查:
sysctl net.ipv4.ipfrag_high_thresh
必要时按官方建议增大这个阈值,不要只盯着 ipfrag_time 一个参数。
(三)大消息问题别再按“小消息思路”排
传图像、点云、大数组时,问题常常不在发现,也不在 QoS,而在大包本身的传输行为。 这类问题如果还沿用“小消息那套排法”,很容易一直在 Topic 名字、节点状态、echo 现象上打转,却抓不到真正的瓶颈。
所以一旦你发现:
- 小消息正常
- 大消息异常
- 或只有高带宽 Topic 出问题
就应该立刻把排障重心切到 DDS tuning 和内核网络参数,不要继续在“发现是不是坏了”上消耗时间。
十三、总结
在 ROS 2 里,ros2 topic list 能看到 Topic,只能说明发现信息已经到了,并不能说明数据已经真正打通。
这类问题更高效的排法,不是围绕业务节点反复猜测,而是把问题拆开来看:
- 先统一环境变量和 RMW
- 再验证发现层
- 再检查 Topic、类型与 QoS
- 再用最小闭环排除业务干扰
- 最后处理多网卡、Docker SHM 和大消息场景
按这个顺序推进后,“Topic 看得到但收不到数据”通常都能收敛为一个可以定位、可以复现、也可以稳定修复的工程问题。
参考链接
正文里的命令和现象,主要按 Humble / Jazzy 常见现场经验整理,如有错误遗漏欢迎指出交流讨论;参考链接优先使用当前较新的官方文档页。不同发行版之间如果存在 CLI 行为差异,应以你当前发行版文档和实际输出为准。
- ROS 2 QoS Settings
- ROS 2 Understanding Topics
- ROS 2 Installation Troubleshooting
- ROS 2 Working with multiple RMW implementations
- ROS 2 Improved Dynamic Discovery
- ROS 2 DDS tuning
- ROS 2 Writing a static broadcaster (C++)
- Fast DDS Discovery
- Fast DDS SHM in Docker
- Fast DDS Interface Whitelist
- Fast DDS Disabling all Multicast Traffic
- Cyclone DDS Networking Interfaces
- Cyclone DDS Discovery Configuration
评论区